专题:DeepSeek为何能编削环球AI圈开云体育
起头:机器之心
咱们齐没预猜想,AI 领域的 2025 年是这么启动的。
DeepSeek R1 果然太利弊了!
最近,‘私密的东方力量’DeepSeek 正在‘硬控’硅谷。
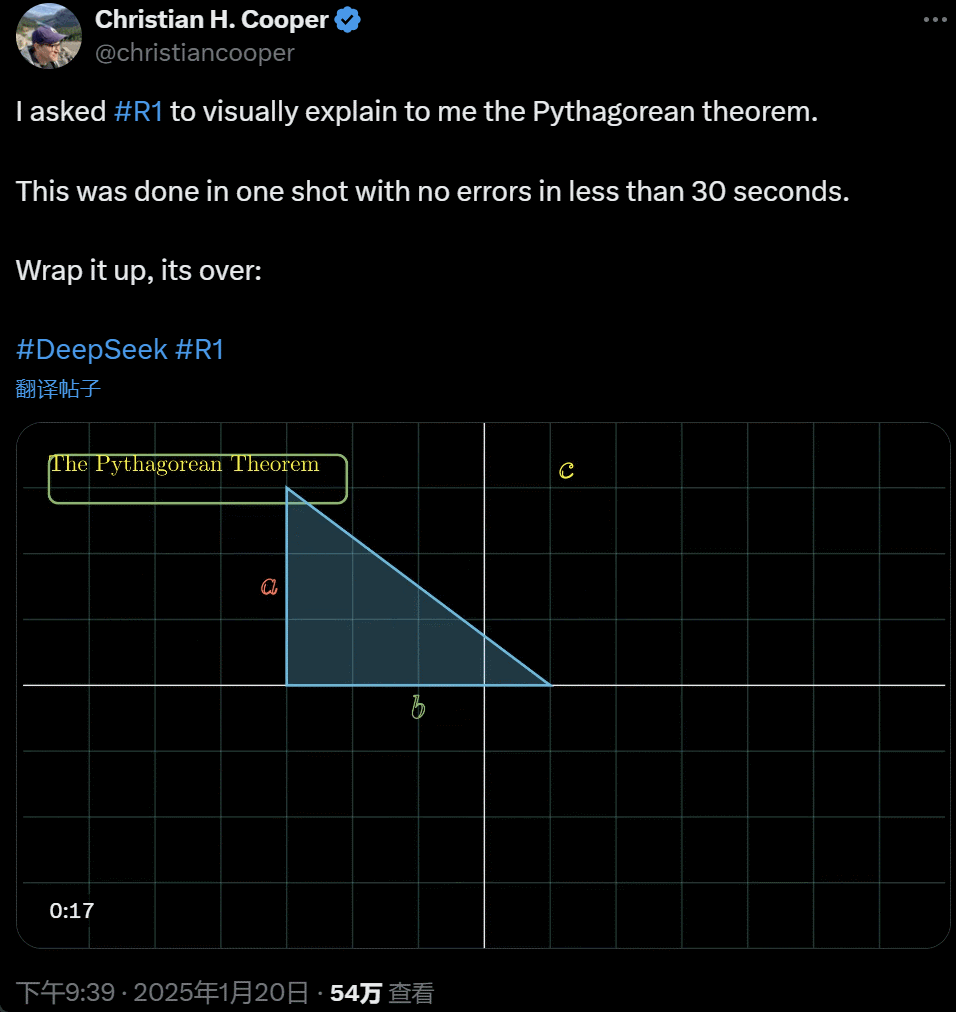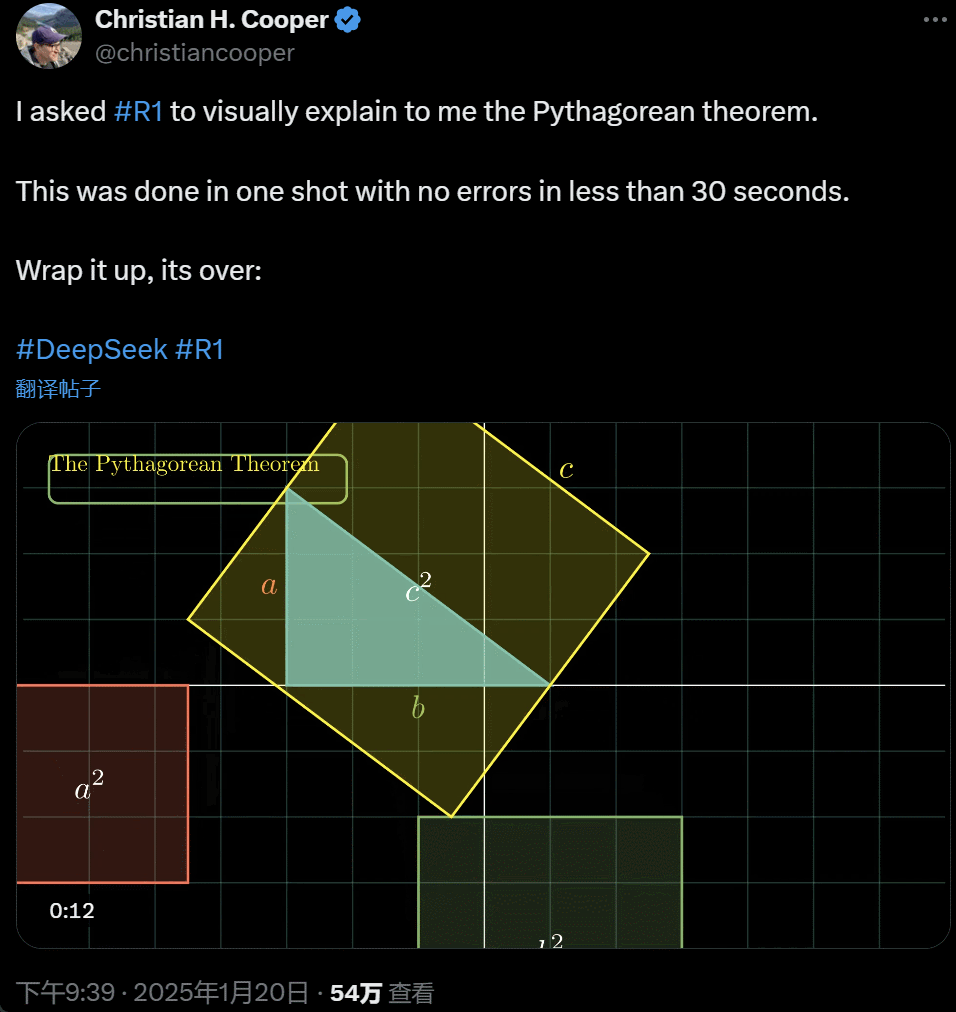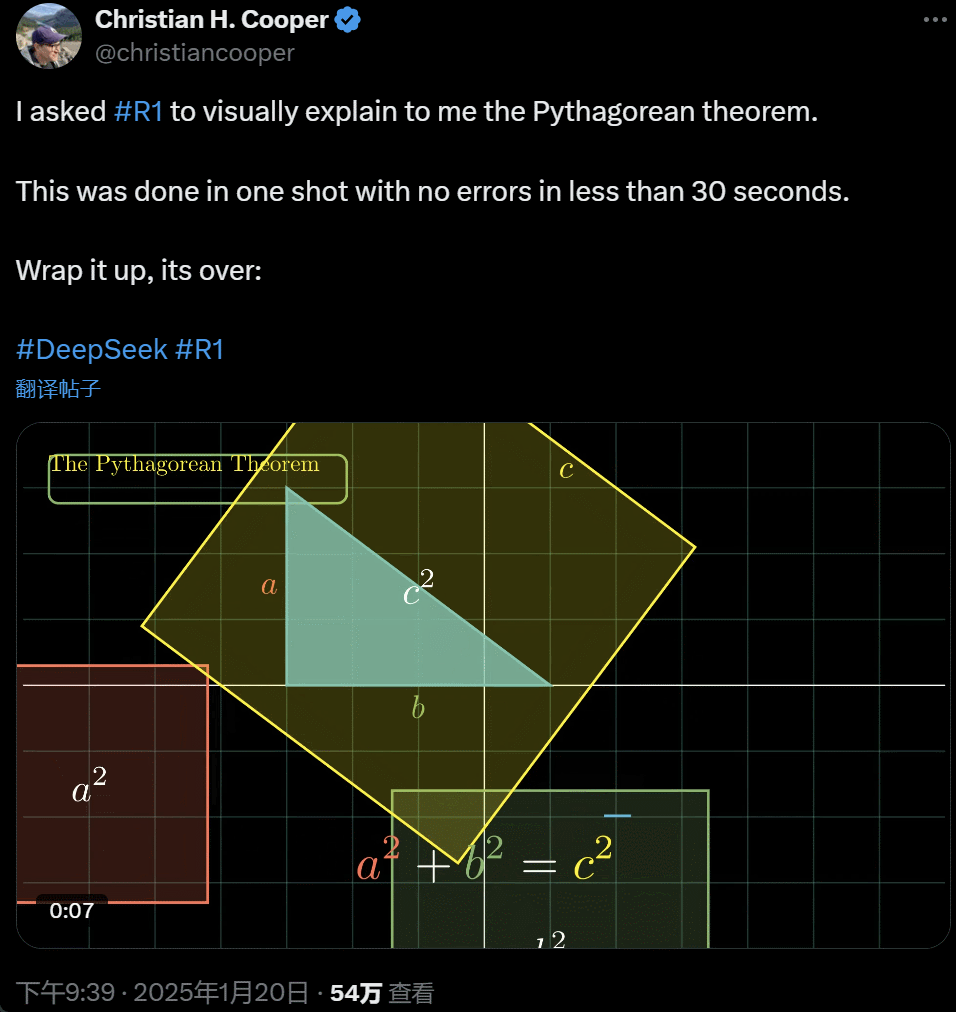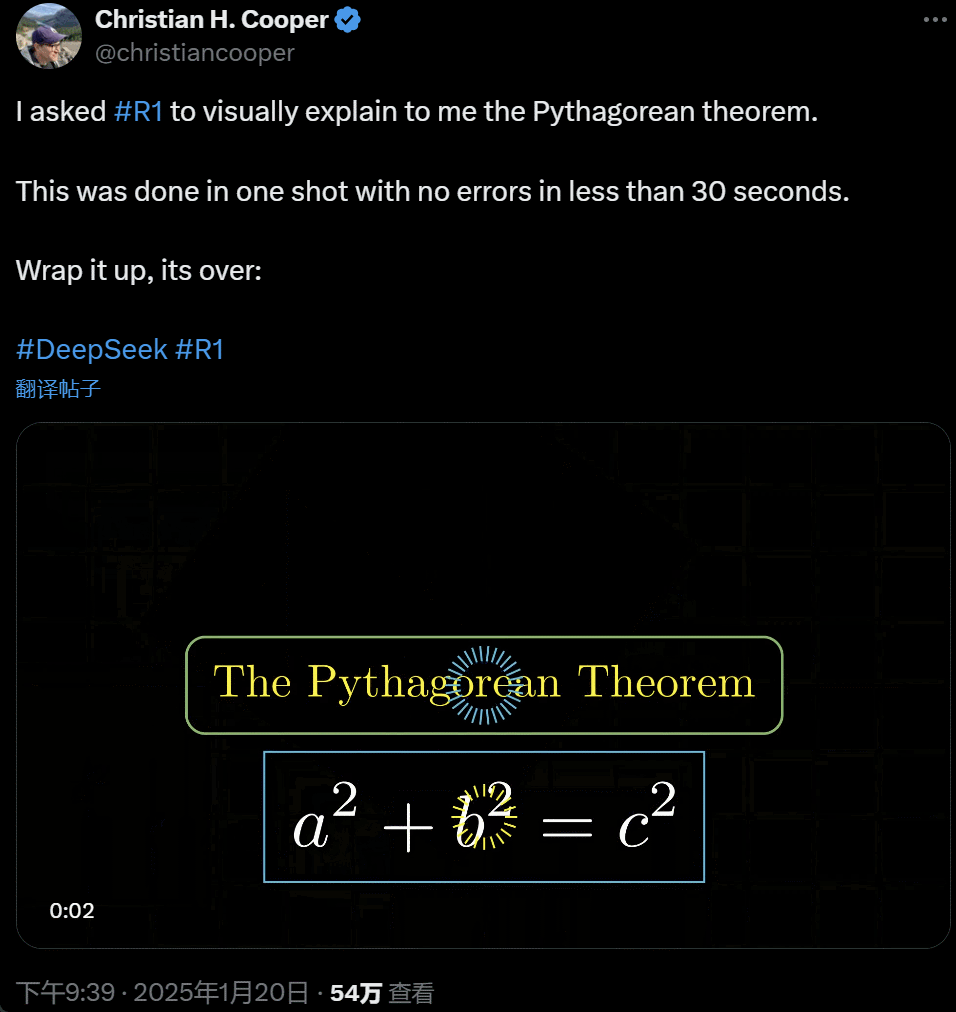
我让 R1 详备解释勾股定理。这一切齐是 AI 在不到 30 秒时刻里一次性完成的,没出任何错。简便来说,its over.
在国表里 AI 圈,粗俗网友发现了神奇的弘大新 AI(还开源),学界众人纷繁喊出‘要不甘雌伏’,还有小谈音信称国外的 AI 公司还是小题大作。
就说这个本周刚发布的 DeepSeek R1,它莫得任何监督试验的纯强化学习路子令东谈主震憾,从客岁 12 月 Deepseek-v3 基座发展到如今堪比 OpenAI o1 的念念维链智商,似乎是很快收尾的事。
但在 AI 社区热气腾腾的读技能敷陈、对比实测之余,东谈主们如故对 R1 有所怀疑:它除了能跑赢一堆 Benchmark 除外,真的能最初吗?
能自建模拟‘物理规章’
你不信?来让大模子玩玩弹球?
最近几天,AI 社区的一些东谈主启动千里迷一项测试 —— 测试不同的 AI 大模子(尤其是所谓的推理模子)来惩处一类问题:‘编写一个 Python 剧本,让一个黄色球在某个体式内弹跳。让该体式闲适旋转,并确保球停留在体式内。’
一些模子在这项‘旋转球形’基准测试中的说明优于其他模子。据 CoreView CTO Ivan Fioravanti 称,国内东谈主工智能实验室 DeepSeek 的开源大模子 R1 完胜 OpenAI 的 o1 pro 形状,后者动作 OpenAI ChatGPT Pro 权术的一部分,每月收费 200 好意思元。

左边是 OpenAI o1,右边是 DeepSeek R1。如上所述,这里的 Prompt 是:‘write a python script for a bouncing yellow ball within a square, make sure to handle collision detection properly. make the square slowly rotate. implement it in python. make sure ball stays within the square.’
字据另一位网友在 X 上的说法,Anthropic 的 Claude 3.5 Sonnet 和谷歌的 Gemini 1.5 Pro 模子对物理旨趣判断特别,导致球偏离了体式。也有效户敷陈称,谷歌最新的 Gemini 2.0 Flash Thinking Experimental,以及相对更旧的 OpenAI GPT-4o 齐一次性通过了评估。
但这里面亦然能分出凹凸的:
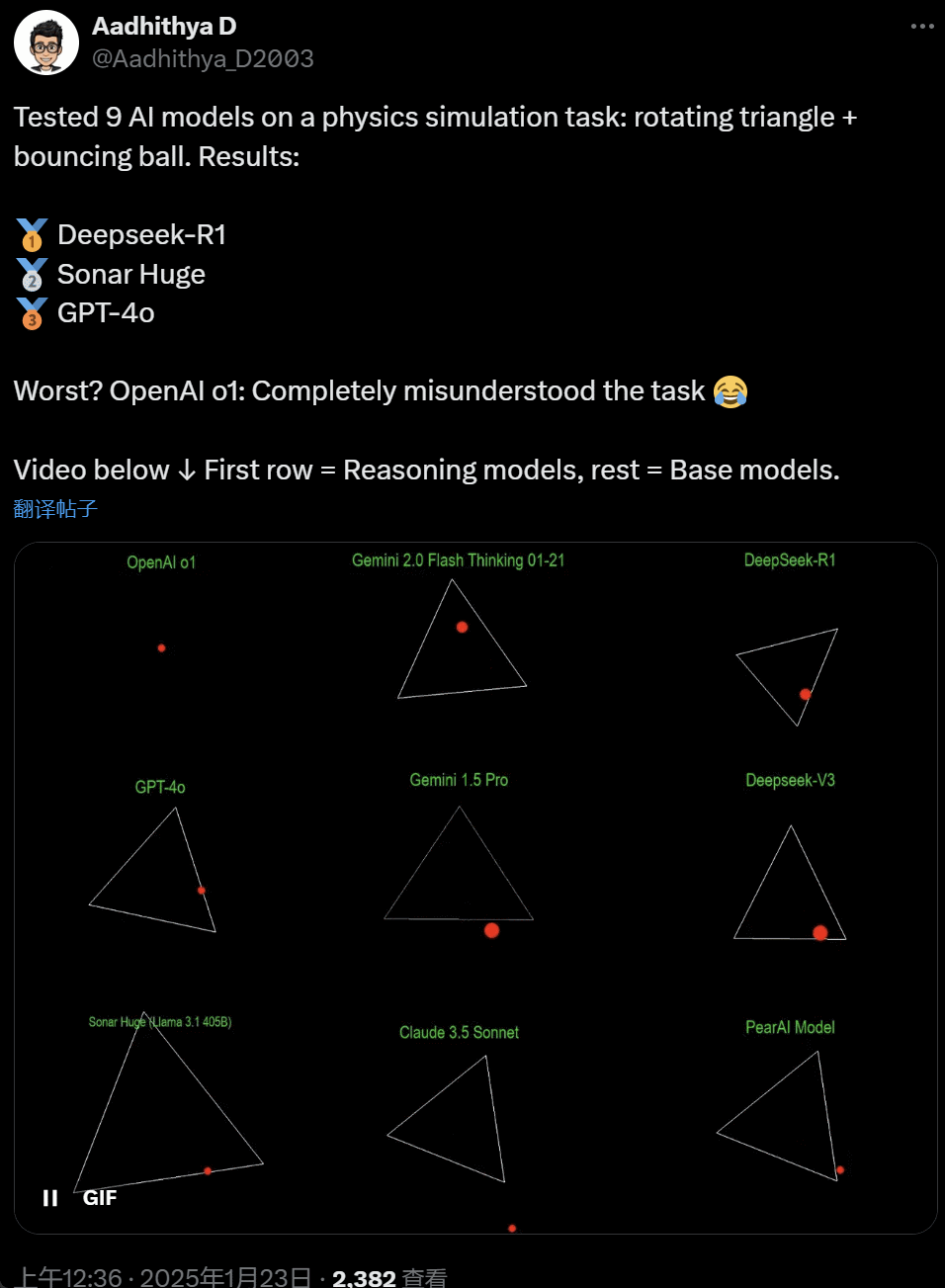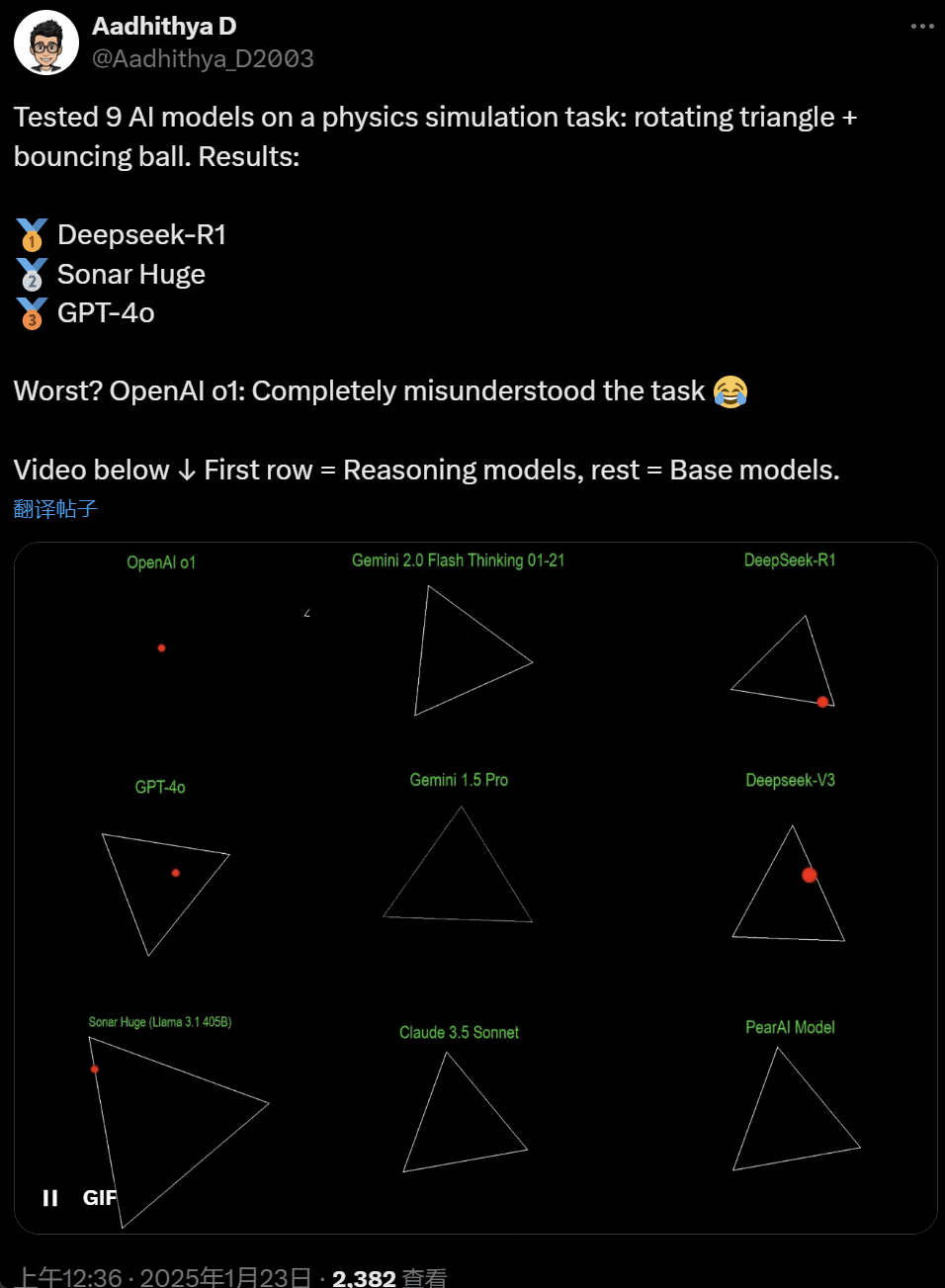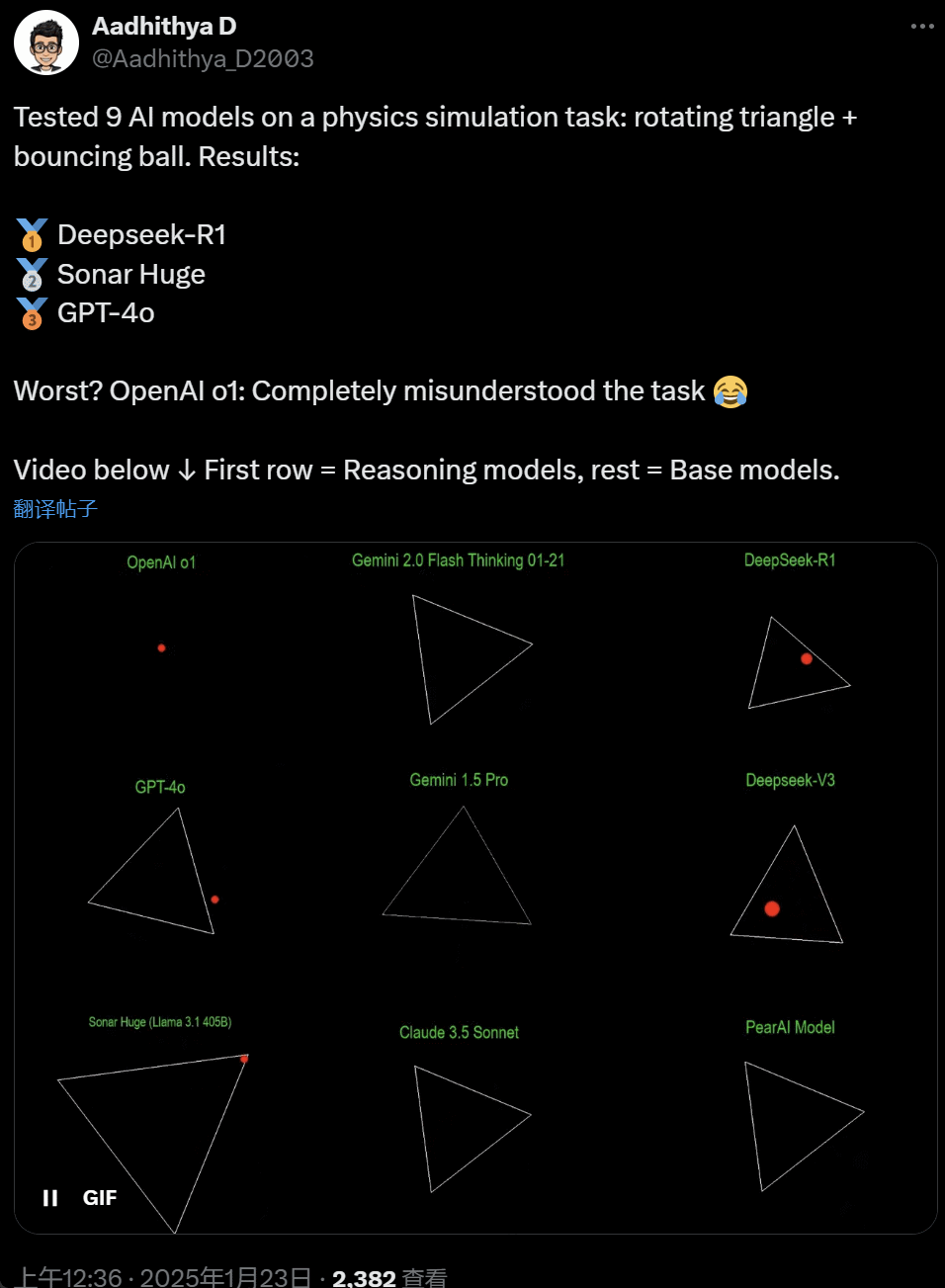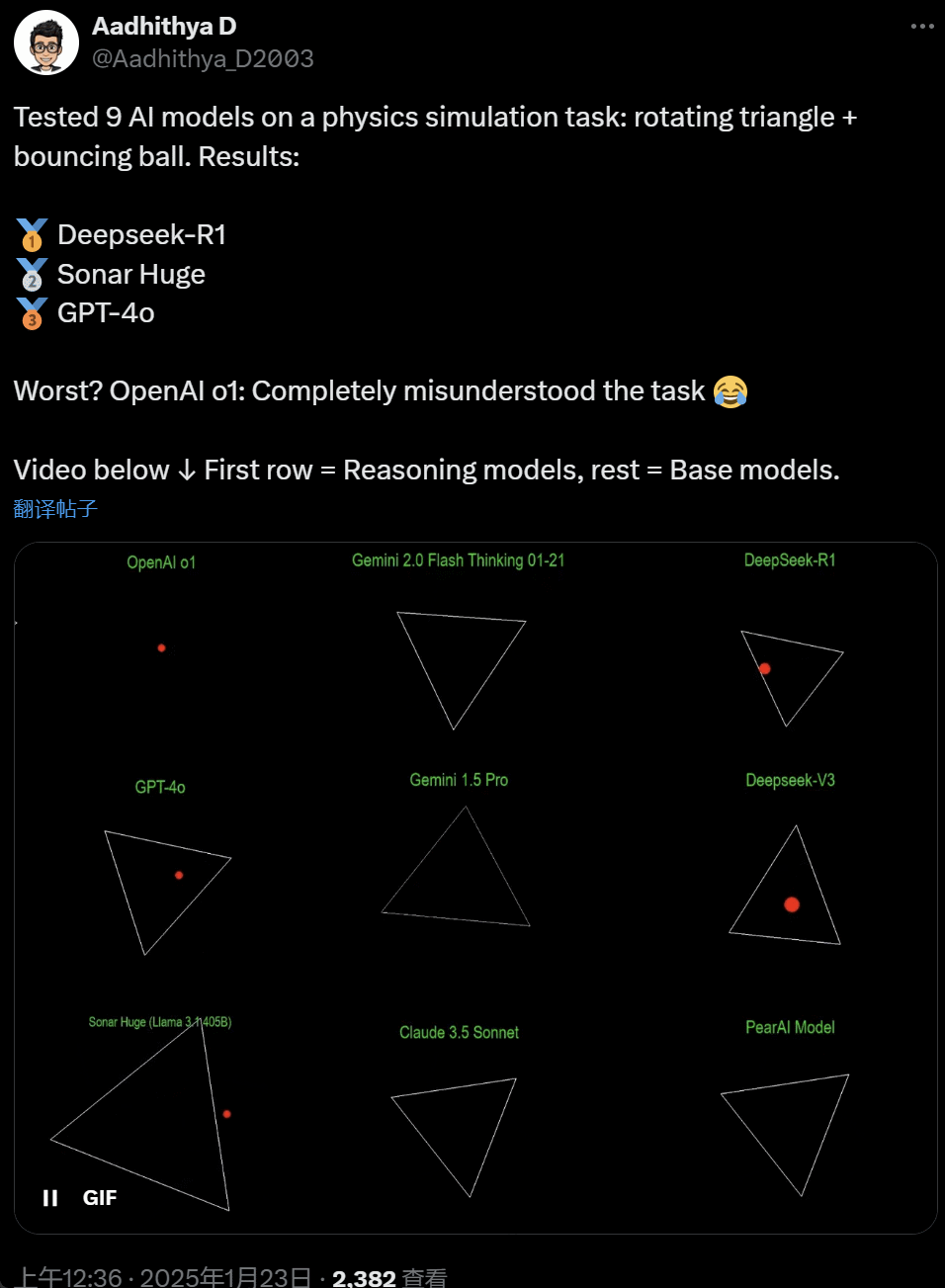
在这个推文下面的网友暗意:o1 的智商原来很好,在 OpenAI 优化速率事后就变弱了,即使是每月 200 好意思元的会员版也相同。
模拟弹跳球是一个经典的编程挑战。精确的模拟勾搭了碰撞检测算法,其算法需要去识别两个物体(举例一个球和一个体式的侧面)何时发生碰撞。编写失当的算法会影响模拟的性能或导致显着的物理特别。
AI 初创公司 Nous Research 的磋磨员 N8 Programs 暗意,他花了苟简两个小时从新启动编写一个旋转七边形中的弹跳球。‘必须追踪多个坐标系,了解每个系统中的碰撞是怎么进行的,并从新贪图代码以使其具有鲁棒性。’
诚然弹跳球和旋转体式是对编程手段的合理测试,但对于大模子来说如故个新表情,即使是辅导中的轻飘变化也可能产生出不同的恶果。是以如果想让它最终成为 AI 大模子基准测试的一部分的话,还需要改良。
不管怎么,经由这一波实测之后,咱们对大模子之间的智商不同有了不雅感。
DeepSeek 是新的‘硅谷神话’
DeepSeek 正让大洋此岸堕入‘战抖’。
Meta 职工发帖称‘Meta 工程师们正在淘气地分析 DeepSeek,试图从中复制任何可能的东西。’
而 AI 科技初创公司 Scale AI 独创东谈主 Alexandr Wang 也公开暗意,中国东谈主工智能公司 DeepSeek 的 AI 大模子性能大致与好意思国最佳的模子尽头。
他还觉得,曩昔十年来,好意思国可能一直在东谈主工智能竞赛中最初于中国,但 DeepSeek 的 AI 大模子发布可能会‘改变一切’。
X 博主 @8teAPi 则觉得,DeepSeek 并不是一个‘副业表情’,而是像洛克希德・马丁以前的‘臭鼬工场’。
所谓‘臭鼬工场’,等于当初洛克希德・马丁公司(Lockheed Martin)为了研发诸多先进航行器专诚成立的一个高度微妙、相对孤立的小团队,从事顶端或相称规的技能磋磨与开采。从 U-2 窥俟机、SR-71 黑鸟,到 F-22 猛禽、F-35 闪电 II 接触机齐是从这里走出来的。
自后,这个词冉冉演酿成一个通用术语,用来样子在大公司或组织里面成就的‘小而精’、相对孤立且解放度更高的更动团队。
他给出的意义有两个:
一方面是 DeepSeek 领有大宗的 GPU,据称有跳跃一万块,而 Scale AI 的 CEO Alexandr Wang 甚而暗意可能达到 5 万块。
另一方面,DeepSeek 只从中国名次前三的大学招聘东谈主才,这意味着 DeepSeek 与阿里巴巴和腾讯具有同等的竞争力。
仅凭这两个事实,就不错看出,清爽 DeepSeek 在买卖上取得了顺利,况且还是填塞有名,省略赢得这些资源。
至于 DeepSeek 的开采资本,该博主暗意,中国科技公司不错赢得多样种种的补贴,比如低用电资本和用地。
因此,DeepSeek 相称有可能大部分资本齐被‘安置’在中枢业务之外的某个账目上,或者以某种数据中心莳植补贴的步地存在。甚而除了独创东谈主之外,没东谈主所有明晰所有财务安排。有些公约可能仅仅‘理论协定’,只靠声誉就能敲定。
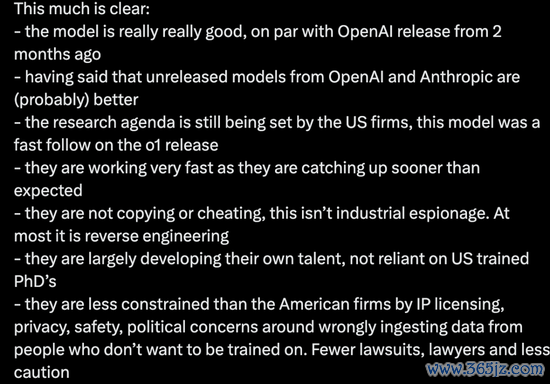
不管奈何,有几点是明确的:
这个模子相称出色,与 OpenAI 两个月前发布的版块尽头,天然也有可能不如 OpenAI 和 Anthropic 尚未发布的新模子。
从当前来看,磋磨主义仍主要由好意思国公司主导,DeepSeek 模子属于对 o1 版块的‘快速跟进’,但 DeepSeek 的研发进程相称迅猛,比预期更快地不甘雌伏,他们并莫得抄袭或舞弊,最多仅仅逆向工程。
DeepSeek 主若是在培养我方的东谈主才,而不是依赖好意思国培养的博士,这大大延迟了东谈主才库。
与好意思国公司比较,DeepSeek 在学问产权许可、狡饰、安全、政事等方面受到的拘谨较少,围绕特别地使用那些不想被试验的数据的担忧也较少。诉讼更少,讼师更少,也更少顾虑。
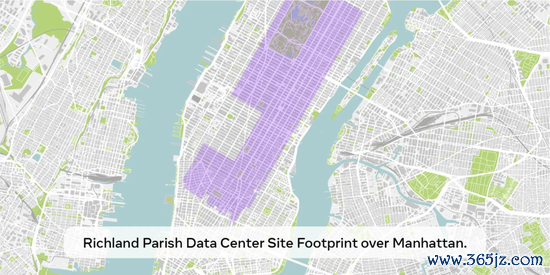
毫无疑问,越来越多的东谈主觉得 2025 年将会是决定性的一年。与此同期各家公司齐在蠢蠢欲动,比如 Meta 就正在建立一个 2GW+ 的数据中心,瞻望在 2025 年投资 600-650 亿好意思元,年底领有跳跃 130 万块 GPU。
Meta 甚而用一张图表展示了 2 千兆瓦数据中心与纽约曼哈顿的对比。
但当今 DeepSeek 用更低的资本,更少的 GPU 作念到了更好,岂肯不让东谈主霸道?
Yann LeCun:要感谢开源
Hyperbolic 的 CTO、鸠合独创东谈主 Yuchen Jin 发帖暗意,在仅 4 天时刻里,DeepSeek-R1 向咱们清楚注解了 4 个事实:
开源 AI 仅逾期于闭源 AI 不到 6 个月
中国正在主导开源 AI 竞赛
咱们正插足废话语模子强化学习的黄金时间
蒸馏模子相称弘大,咱们将在手机上运行高智能 AI

由 DeepSeek 激发的四百四病仍在持续,比如 OpenAI o3-mini 免费可用、社区中但愿能减少对于 AGI/ASI 的迂缓讨论以及外传 Meta 堕入战抖等。
他觉得,当今很难预测最终谁会顺利,但不要健忘后发上风的力量,毕竟咱们齐知谈是 Google 发明了 Transformer,而 OpenAI 解锁了其确实后劲。
此外,图灵奖得主、Meta 首席东谈主工智能科学家 Yann LeCun 也抒发了我方的概念。
‘对于那些看到 DeepSeek 的性能就觉得“中国正在突出好意思国的 AI”的东谈主,你领路错了。正确的领路是:开源模子正在突出特别模子。’
LeCun 暗意,DeepSeek 之是以此次一鸣惊东谈主,是因为他们从通达磋磨和开源(如 Meta 的 PyTorch 和 Llama)中获益。DeepSeek 建议了新想法,并在他东谈主责任的基础上构建。因为他们的责任是公开采布和开源的,每个东谈主齐不错从中受益,这等于通达磋磨和开源的力量。

网友们的反念念还在持续,在对于新技能发展振奋的同期,也能感受到小数点忧虑的悔恨,毕竟 DeepSeek 们的出现,可能会带来真金白银的影响。
参考推行:
https://x.com/ivanfioravanti/status/1881969391547683031
https://x.com/Aadhithya_D2003/status/1882105009548222953
https://x.com/8teAPi/status/1882836551866204656
https://x.com/Yuchenj_UW/status/1882840436974428362
https://x.com/ylecun/status/1882943244679709130
https://venturebeat.com/ai/tech-leaders-respond-to-the-rapid-rise-of-deepseek/
 海量资讯、精确解读,尽在新浪财经APP
海量资讯、精确解读,尽在新浪财经APP
遭殃裁剪:丁文武 开云体育


